
The screenshots in this talk have been taken 1 from the LCA LiveCD. You don't need anything more than the software distributed on the LiveCD to try many of the techniques and tools in this paper.
Simulation is just another kind of simplification. Linux is full of such simplifications called "Standard Interfaces".
For example in the Linux kernel there is a Virtual FileSystem (VFS) API through which many different filesystems can be addressed. Filesystem details change but authors of unrelated software who write to the VFS interface aren't affected by them. At a higher level, that's what the RFC specifications for TCP/IP are about.
Full systems simulation is about keeping virtual hardware constant as real hardware changes underneath.
Imagine you have an operating system that runs on MIPS hardware, a Cisco for example. So you create some MIPS hardware in software, good enough to boot the operating system. This "software hardware" can then keep the OS running no matter what the day-to-day requirements of the underlying platform are. You might change from Pentium to Opteron to Mac G5. The MIPS OS just keeps running in its isolated virtual world.
Within Linux there is a huge push to develop standard interfaces like this. No wonder the Linux-using community finds it easy to make the leap to treating hardware as a "standard interface"!
There is a kind of a triumvirate that has conspired to keep virtualisation on the fringes of IT activity:
Informal analysis indicates that in any given simulation situation two of the above apply, for example:
These considerations have kept simulation largely out of the mainstream.
Total Cost of Ownership (TCO) issues haven't to date been sufficient to cause IT professionals to look for whole new classes of solution. Rather, TCO concerns have been driving a wave of tweaking where hardware-centric and PC-centric ways of doing things are finessed. These approaches are being exhausted, forcing other techniques to be considered. Simulation is one possibility.
And on the modelling side, there is virtually no tradition outside academia of creating virtual equivalents of real networks. Modelling is a predictive and educational tool, and production computer networks full of real users and real applications are not easily predictable -- so why isn't it used more? Perhaps as simulation-based modelling tools become better the concept will become more popular.
Modelling and testing higher-level systems is an approach which is coming to the attention of mainstream IT professionals.
A good illustration of the need is to ask any gathering of networking specialists how many of them test their firewall changes in a dummy environment before going live. The answer is usually close to none! Reasons include that it has been difficult to create test networks and that "it isn't what you do". Ask the same group of people how often they have accidentally interrupted users with imperfect firewall changes and you'll usually get a large range of confessions :-)
By 'higher-level' systems I mean collections of components in a network. Several servers running applications connected by routers and a firewall to a number of clients is, in total, a higher-level system. Probably most people who have built a server have subjected it to some level of testing. But they probably didn't create a virtual server and test it with the target database workload first to see how much memory it was best to give it.
Factors which make whole-system testing more important:
I am investigating the proposition that 'emergent networks' are best stressed by 'emergent testing'. Genetic algorithms tuned for negative events such as operating system crashes or network storms can be used to drive testing of entire systems. I am only in the very early stages of this.
One relatively new application for simulation is in response to changes in IT infrastructure life-cycle. We are seeing software obsolescence getting slower while, at least according to corporate policies, hardware obsolescence is steady. This is a bit like the classic economic problem of an ageing population -- who is going to care for grey-haired applications that refuse to die? :-)
For production systems 'not connected to the Internet', software obsolescence is slowing. Not that the rate of change in either software or user needs is slowing, but the software systems deployed often have a longer lifespan than they did 10 years ago. This is especially true for midrange and smaller systems, which despite their size and investment often become mission critical.
As evidence of this, take Linux systems around the year 2000, or even Windows 2000. For all their faults these operating systems are still deployed in the millions. Many corporate users find they do the job as well today in 2004 as they did in 2000. In contrast, this was often not so in 2000 for operating systems released in 1996. One of the reasons is that operating systems of the 2000 era are quite expandable. If load doubles or database size doubles there is a reasonable chance that Linux 2.4 or (to a lesser extent) Windows 2000 can manage. In 1996, a doubling of load was often quite a challenge for Linux 2.2 and Windows NT very quickly ran into grief.
Linux is an ideal platform for keeping such old-but-still-good systems running without change as their original target hardware moves on, whether the application runs on Linux, Windows, or even Solaris or other operating systems.
Two counterpoints to mention, but not discuss further:
I do not see a corresponding improvement in the perceived lifespan of hardware. Many corporate users have been sticking to a three year life-cycle for their hardware. We already see a trend where software solutions outlast the hardware they were built for. This is likely to increase, given that many low-to-medium level software solutions are lasting longer.
There are some hardware solutions designed to last for many years, such as embedded systems in industrial automation. In this case, the hardware may outlast the utility of the software it was deployed with. I do not consider these systems further.
In these cases, simulation can be used to smooth out the mismatch between current (say, year 2000 onwards) software and the hardware it was intended to run on. There is risk and expense in migrating to new hardware platforms even if the operating system is the same. Simulation may be an answer, where a complete real system is encapsulated and run in a simulated environment without the target operating system noticing.
Linux is the platform around which, with or from which have sprung most modern simulation technologies. Even those closed-source simulators designed exclusively for Windows on x86 as a host or target do not ignore Linux. Conversely many simulation technologies ignore Windows.
Let's look at four kinds of simulation tools, broken down in an unscientific but pragmatic manner based on what is readily available:
It is hard to compare simulation technologies because they are so diverse. For this talk I have devised a very simple table to compare simulation technologies according to five criteria. This table is presented for each of the simulation technologies demonstrated.
Xcopilot is an old but still useful simulator. It is a software implementation of a Palm Pilot III, which uses an MMU-less Motorola CPU. After Xcopilot was written, uClinux became popular with the rise of cheap embedded boards with the same CPU and features such as multiple ethernet cards.
The uCLinux kernel (which includes applications) boots inside XCopilot. Attendees at Linux.conf.au received a modified Knoppix live CD where the initial greeting screen is a web page served by a web server running inside Xcopilot.
| Parameter | Value |
|---|---|
| Synthetic simulation | Yes |
| Accuracy | Fairly |
| Architectures | 1 |
| Speed | Real world or better |
| Pieces to email | 2 |
Figure 1: Networked Xcopilot
When the LiveCD boots it displays an informative web page from the machine uclinux.example.com. This virtual machine is uCLinux running on a virtual Palm Pilot (Xcopilot) which provides an MMU-less Motorola 68k CPU. Networking is via ppp, which on the uCLinux side is via a virtual serial port. Right-clicking on Xcopilot brings up a menu of operations. This is one of the simplest fully synthetic simulators around.
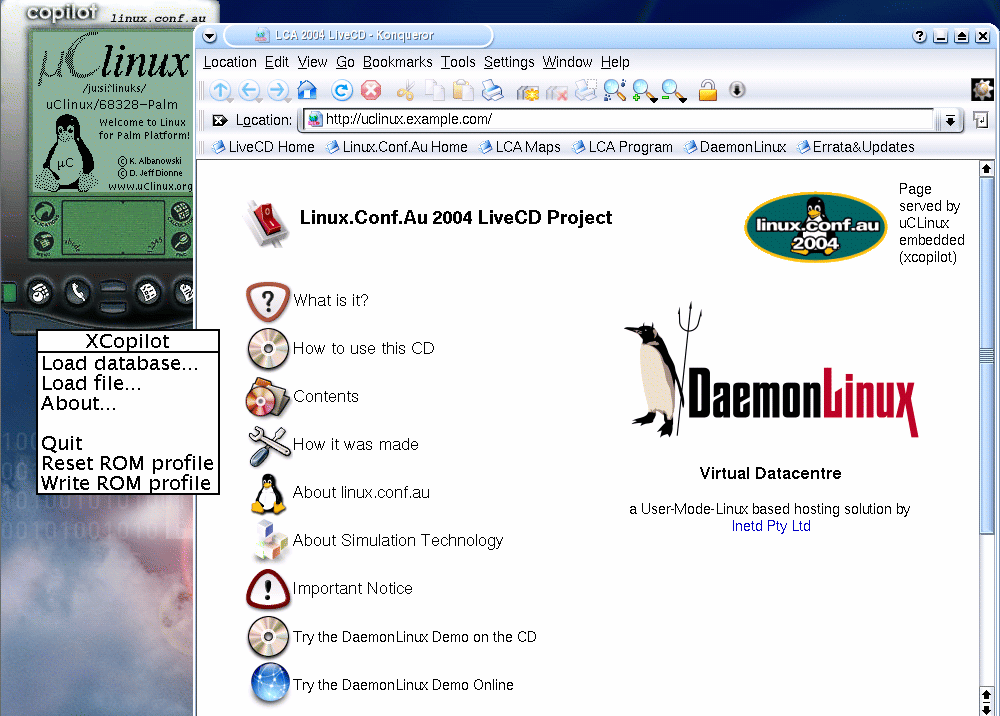
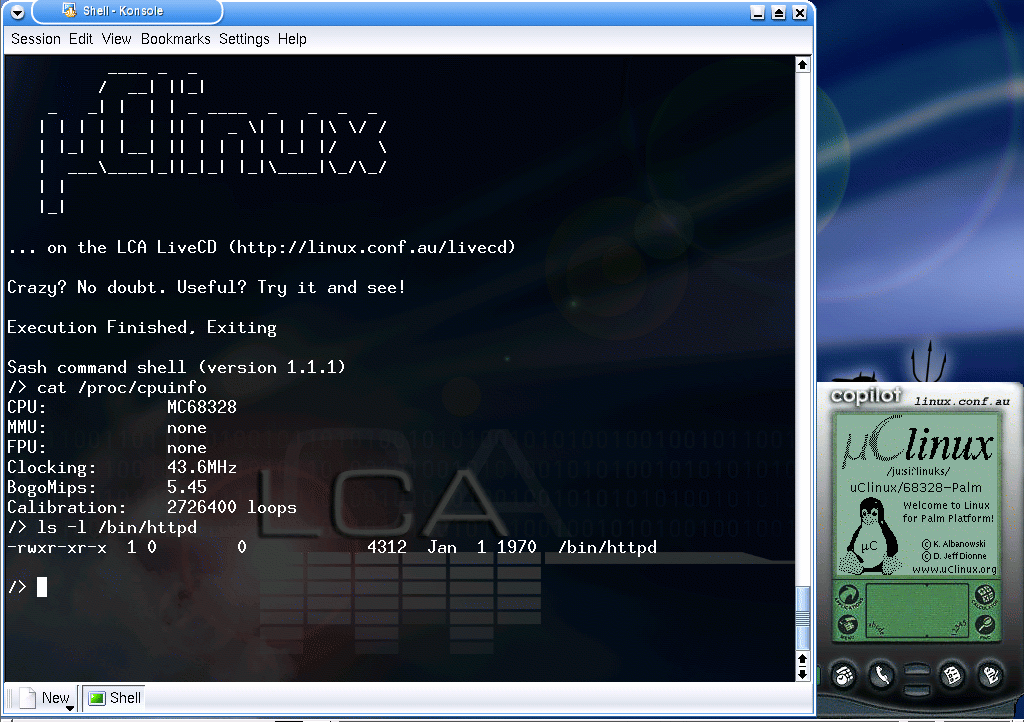
Figure 2: Xcopilot Prompt
Starting Xcopilot without the ppp networking link takes you to the uCLinux commandline, after displaying the motd. Here we show the details of the virtual CPU, which claims to be running at more than twice the speed of any PalmPilot of its day. You can also see the 4k webserver binary. This is very much an embedded platform!
Bochs is one of the older and better-known OSS simulation tools, implementing a 32-bit Intel-compatible architecture. In recent years it has been extended to implement AMD 64-bit instruction set. Bochs is a fully portable application with a functional but elderly wxWindows GUI interface. It can also be run in batch mode.
Bochs is not very efficient, nor does it represent any real hardware you are likely to be able to purchase: a top flight modern processor with 10 year-old IDE hardware? Unlikely. However the very diversity and variable quality of x86 hardware is in this case a virtue, because OS kernels (especially free OSs) are very forgiving in the hardware and hardware combinations supported. This means that many commodity operating systems will install and boot happily on Bochs even though they were probably never tested against hardware that looked anything like it.
| Parameter | Value |
|---|---|
| Synthetic simulation | Yes |
| Accuracy | Not really |
| Architectures | Hotchpotch |
| Speed | ~ -80x target hardware |
| Pieces to email | 3 |
Figure 3: Bochs Boot
This is the main Bochs window, running in GUI mode under Intel 32-bit Linux (from the LCA LiveCD.) In the background is the Bochs master console with status information about the virtual machine. This shot was taken just as the virtual machine has booted, executed its BIOS and loaded the NetBSD boot sector.
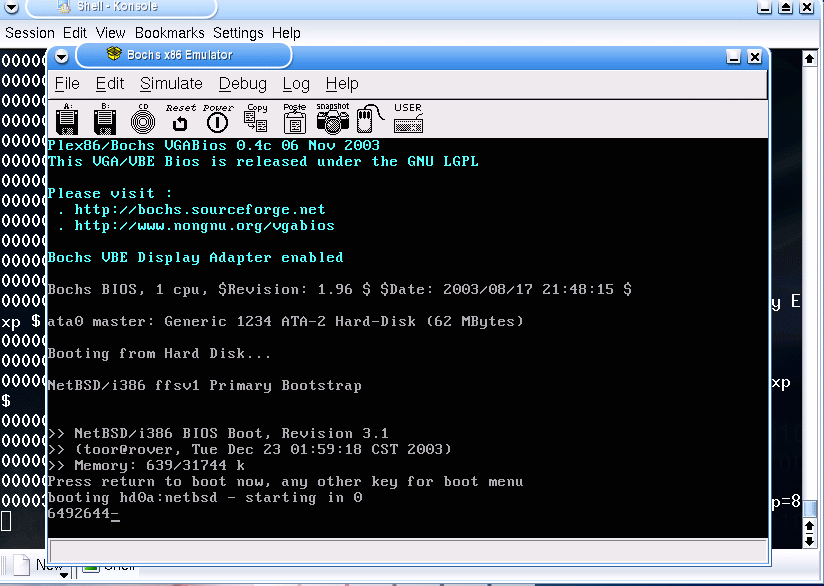
Figure 4: Bochs Detection
Here NetBSD has started its bootstrap, including hardware detection. This is often the biggest test for a simulator's accuracy because kernel developers often have never allowed for hardware behaving in impossible ways. NetBSD has successfully probed for a CPU, bus and RAM. Bochs can implement multiple processors and (using sparse files) terrabytes of storage and other things completely divorced from the host system.

User Mode Linux is a port of Linux to its own system call interface. Think of it as just another porting target for Linux -- IA-64, UltraSPARC, and now User Mode Linux (UML). The UML source tree has about 30k lines of code. This code is the glue between the target Linux kernel and what the target kernel thinks is hardware but in fact are the standard user-space libraries on the host Linux machine. The entire operating system is run within user space, that is, with no more privileged access than the program /bin/ls. In addition the operating system can be run with the privileges of a specific user, which may be much more restricted again. For example, the UML user could be prevented from creating any files on the host or executing any programs.
UML was written for Linux/IA-32, however ports exist for Linux/IA-64 (in progress) and Linux/PPC-32 (stalled.) There is no reason why User Mode Linux cannot be ported to operating systems other than Linux so long as they have a Linux-like system call interface. There are no such ports currently useable, although an older version of UML was ported to run under Windows via Cygwin and got to running /usr/bin/vi in single user mode!
UML differs markedly from Xcopilot because despite the synthesis of much of the hardware the actual machine instructions and above all the memory operations are executed on real hardware.
| Parameter | Value |
|---|---|
| Synthetic simulation | No |
| Accuracy | Perfectly (defines its own architecture) |
| Architectures | Hotchpotch |
| Speed | 0.75 x underlying host hardware |
| Pieces to email | 2 or so |
Figure 5: UML Boot
Starting UML is just like starting any other user-mode program, from /bin/ls to mozilla. In this case the program happens to be a special version of the Linux kernel, so it displays very familiar messages as it loads. The UML kernel thinks it is booting on hardware. You can see the UML-specific commandline switches which tell the kernel about its virtualised peripherals.
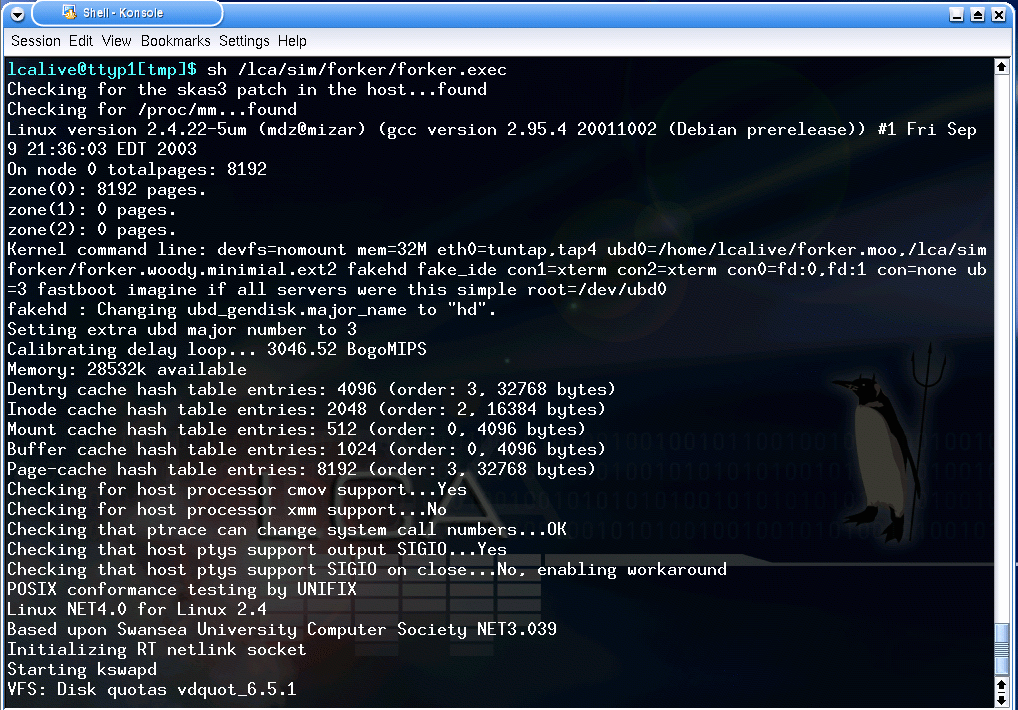
Figure 6: UML Multiuser
Here UML has booted into multiuser mode (runlevel 2, in Debian) and initialised its virtual consoles. The root console is the original window to the left. In the real world a virtual console is accessed by Alt-F1, Alt-F2 etc and the Linux kernel manipulates the video hardware appropriately. In this case there is no video hardware so the different virtual terminals are implemented as xterm windows.
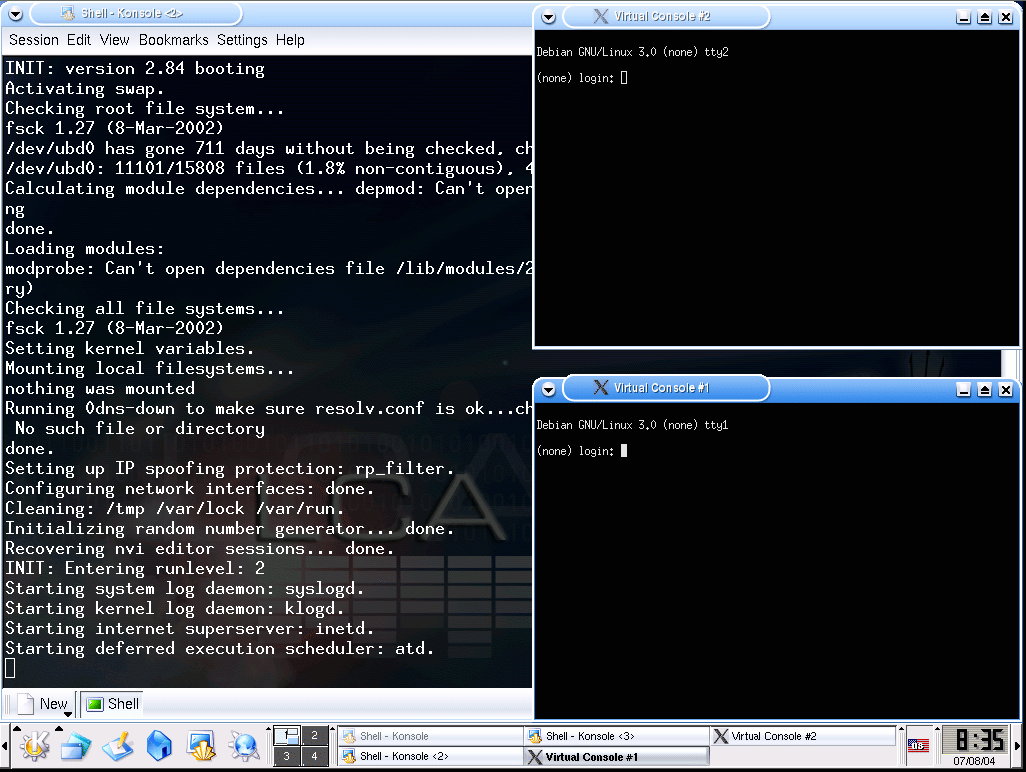
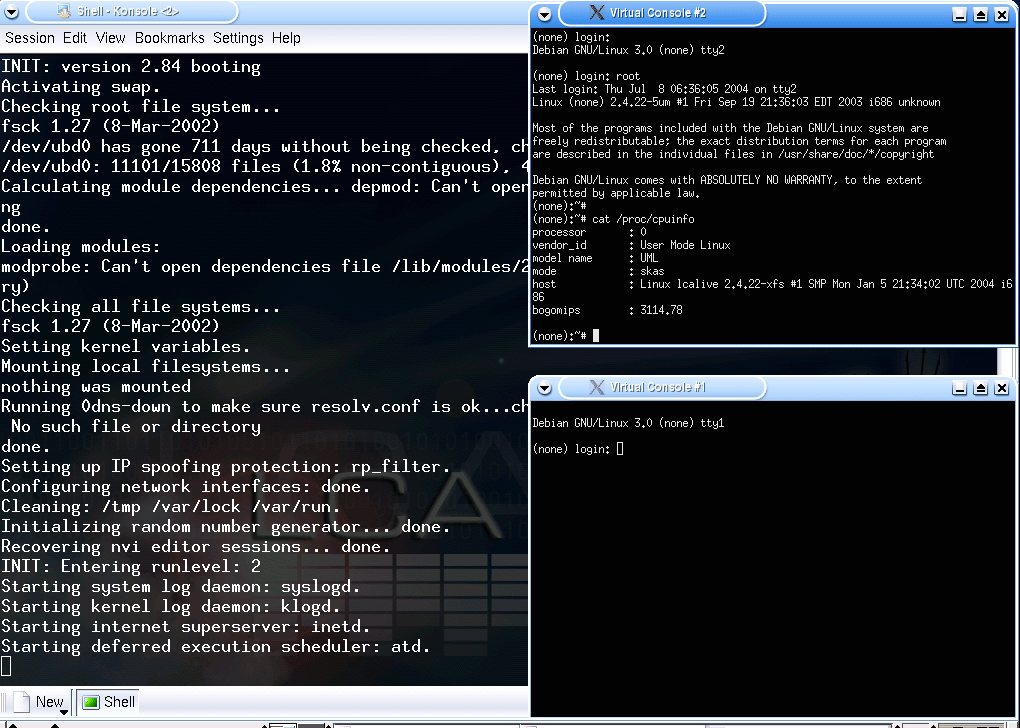
Figure 7: UML Login
We log on to one of the virtual consoles and look at the CPU: it is clearly not running on real hardware!
Hercules gets back to the Xcopilot-style synthetic hardware. It is an implementation of several IBM mainframe architectures, from S/370 to S/390 (31-bit) to zSeries (64-bit) with up to four processors, and a reasonable range of authentic-looking peripherals. I say "authentic-looking" because I don't really know. Most of this sort of hardware was popular when I was a little boy!
Hercules runs Linux/390 very well. It isn't a very efficient simulation engine, but it is reliable. The inefficiency is relative: once installed it is quite fast enough to serve pages live on the Internet from a LAMP (Linux-Apache-MySQL-PHP) application.
Real 64-bit hardware is not difficult to find these days thanks to AMD and, to a lesser extent, Apple. But even so many people do not have access to 64-bit platforms and yet need to test their code to make sure it is 64-bit clean. I recommend Hercules for this task, combined with distcc and ccache it is a perfectly respectable compilation environment.
And, besides, it is just plain fun. When you get tired of running 64-bit Linux for zSeries on a 4 CPU machine with lots of resources, you can download, install and run OS/360 version 28.1 and be in a vintage 1970s computing environment. Some people have even put their OS/360 instances on the Internet. It's quite secure, probably not one person in ten thousand has any idea how to log on to OS/360 let alone do any damage :-)
| Parameter | Value |
|---|---|
| Synthetic simulation | Yes |
| Accuracy | High |
| Architectures | At least 3 |
| Speed | -90x target hardware |
| Pieces to email | 2 or so |
Figure 8: Hercules HMC
Welcome to the Hardware Management Console (HMC) of an IBM S/390 mainframe. In real life on z-Series machines it is an IBM Thinkpad laptop running OS/2 and dedicated software that makes it look like an old-fashioned 9672 terminal... so we already have a few layers of virtualisation before Hercules is considered! The PSW is Program Status Word, known as "Instruction Pointer" on other architectures. All counters are zero because the machine has not yet been told to boot. The console is alive (ie, the laptop is running its terminal software.) In Unix terminology the mainframe is talking back in single user console mode.
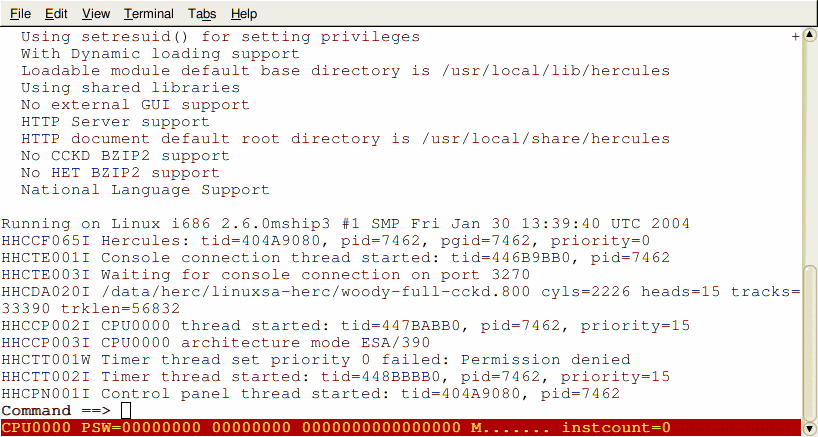
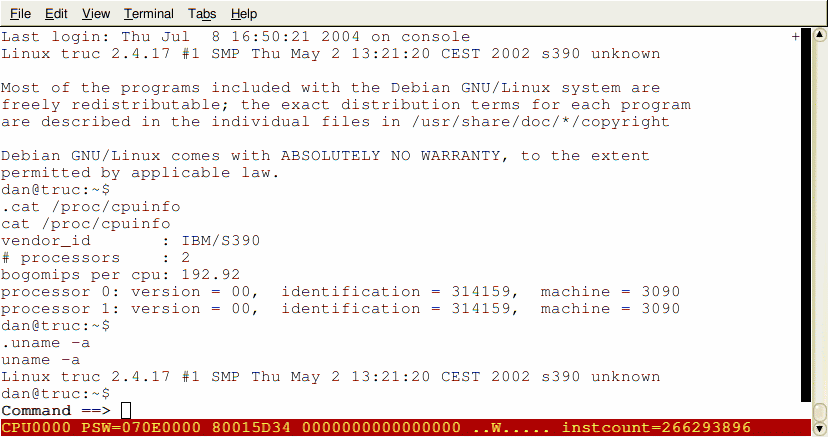
Figure 9: Hercules Login
After issuing the command "IPL 0800" for Initial Program Load from the device found at address 0800 (approximately speaking) a normal-looking Linux boot sequence takes place. We are still interacting with the virtualised HMC, where the rule is that any commands prefixed by a "." are passed through to the mainframe session and anything else is interpreted as an HMC command. An alternative is to connect via a 3270 session or a TCP/IP connection over ssh or X11/xterm etc. Here I have logged in and we can see that Linux/390 thinks it is running on a dual processor S/390 (as it happens, the underlying hardware is a single-processor 32-bit Intel machine.) A single change in the Hercules configuration file and this would be a 64-bit zSeries mainframe. The reported bogomips is an order of magnitude slower than with User Mode Linux because of UML's unique hybrid design -- fully synthesised yet also native code execution. The S/390 has a unique CPU ID used for many things especially software licensing. Thanks to Hercules' configuration file we are able to change it to any desired value, for example Pi as illustrated.
Exim is a free mail transport agent, a bit like qmail only a little less so. The Exim author is present at this conference and he has an interesting problem in his project in common with many others: how to communicate a test suite to users without perturbing it?
We are not considering a test suite in the sense of software unit tests, but whole-system testing where an MTA connects to an other system and has an SMTP conversation, probably after consulting DNS, negotiating a firewall and coping with changing network conditions.
The issue with an MTA is that proper testing requires a lot of setup, some of it quite complicated. Multiple good and bad DNSs are required; good and bad clients; good and bad servers; fast and slow and error-prone networks; buggy hosts and more. It would be ideal if a little artificial world for testing Exim could be created so that all testers could start from the same parameters.
Every testing environment has bugs, as well as the software being tested. Hopefully over time a testing environment which is available to all will be improved just as the software being tested improves through the open source process.
'One thing to be wary of is only ever testing within a single environment, no matter how realistic. Monoculture testing breeds bugs. Nevertheless, many bugs are squashed with a comprehensive test suite.'
So, the goals for a suitable test rig are:
One way to meet these goals is to use User Mode Linux. We can create an image containing:
This image would be about 40Mb compressed, and that is allowing for a fairly full Linux distribution. The way to invoke this would be to have a standard UML binary, usually installed by your distribution maintainer, that you start with a command such as:
You can implement networks of varying capacity and quality using fake ethernet devices (with the tap ethernet driver) and with clever iptables rules to for rate limiting and other features.
This is very much a simple case and usually you will add options. But this gives the idea: just a single ~40Mb image and a standard UML binary (maybe from `apt-get install uml`).
There are problems with this model of a test environment, the biggest one being that there is not much separation between the various configurations for daemons. Having many different configurations for DNS, Exim and other programs all active at once on the one computer at once is asking for trouble. At the very least it will require a lot of debugging and testing to get right!
A more elegant solution is to more closely model the real world by having a number of virtual machines, each running a more usual number of services. This should be easier to create and debug.
There is also the advantage that different Linux distributions can be used in order to expose Exim to a broader range of libraries and default installation mechanisms. This might increase maintenance overhead a little because each distribution has a different way of keeping up to date with patches and upgrades. On the other hand, it is possible to eliminate this problem altogether by making the image for each virtual machine just a copy of the main virtual machine, at the cost of diversity.
Most Linux distributions ship UML with nesting enabled to 1 level deep (the default.) If you wish to be absolutely sure you could also email the binary, there is a good chance it will work on most 32-bit Intel distributions with current libraries and a 2.4 or higher kernel.
Regardless of the detailed design decisions, the overall picture is of a master UML root filesystem image containing:
This would probably add up to 100Mb compressed.
Simulation is practical, tools abound... and simulation without Linux would be like the Internet without Open Source. Unlikely to the point of vanishingly remote, and unthinkably boring :-)
Thankyou!
[1] - except for Hercules
This document was generated using AFT v5.094